Ok, it seems we didn’t take into consideration that we have in our workflow a simpleFilterTask that removes first dimension slices from the eopatches.
filter_clouds_task = SimpleFilterTask((FeatureType.MASK, 'CLM'), filter_clouds)
So there indeed seems to be in this example 103 passed requests.
DEBUG:eolearn.core.eoworkflow:Computing SimpleFilterTask(*[EOPatch(
data={
BANDS: numpy.ndarray(shape=(103, 156, 199, 12), dtype=float32)
CLP: numpy.ndarray(shape=(103, 156, 199, 1), dtype=uint8)
sunAzimuthAngles: numpy.ndarray(shape=(103, 156, 199, 1), dtype=float32)
sunZenithAngles: numpy.ndarray(shape=(103, 156, 199, 1), dtype=float32)
viewAzimuthMean: numpy.ndarray(shape=(103, 156, 199, 1), dtype=float32)
viewZenithMean: numpy.ndarray(shape=(103, 156, 199, 1), dtype=float32)
}
mask={
CLD: numpy.ndarray(shape=(103, 156, 199, 1), dtype=uint8)
CLM: numpy.ndarray(shape=(103, 156, 199, 1), dtype=uint8)
dataMask: numpy.ndarray(shape=(103, 156, 199, 1), dtype=bool)
}
meta_info={
maxcc: 1
size_x: 199
size_y: 156
time_difference: 7200.0
time_interval: ('2020-10-14T00:00:00', '2021-07-01T00:00:00')
}
bbox=BBox(((238810.0, 3774970.0), (240800.0, 3776530.0)), crs=CRS('32630'))
timestamp=[datetime.datetime(2020, 10, 15, 11, 11, 59), ..., datetime.datetime(2021, 6, 30, 11, 21, 53)], length=103
)], **{})
DEBUG:eolearn.core.eoworkflow:Removing intermediate result of download_task (node uid: SentinelHubInputTask-1bbabc5e999f11ecb27c-7910df318da1)
DEBUG:eolearn.core.eoworkflow:Computing AddValidDataMaskTask(*[EOPatch(
data={
BANDS: numpy.ndarray(shape=(48, 156, 199, 12), dtype=float32)
CLP: numpy.ndarray(shape=(48, 156, 199, 1), dtype=uint8)
sunAzimuthAngles: numpy.ndarray(shape=(48, 156, 199, 1), dtype=float32)
sunZenithAngles: numpy.ndarray(shape=(48, 156, 199, 1), dtype=float32)
viewAzimuthMean: numpy.ndarray(shape=(48, 156, 199, 1), dtype=float32)
viewZenithMean: numpy.ndarray(shape=(48, 156, 199, 1), dtype=float32)
}
mask={
CLD: numpy.ndarray(shape=(48, 156, 199, 1), dtype=uint8)
CLM: numpy.ndarray(shape=(48, 156, 199, 1), dtype=uint8)
dataMask: numpy.ndarray(shape=(48, 156, 199, 1), dtype=bool)
}
meta_info={
maxcc: 1
size_x: 199
size_y: 156
time_difference: 7200.0
time_interval: ('2020-10-14T00:00:00', '2021-07-01T00:00:00')
}
bbox=BBox(((238810.0, 3774970.0), (240800.0, 3776530.0)), crs=CRS('32630'))
timestamp=[datetime.datetime(2020, 10, 18, 11, 21, 55), ..., datetime.datetime(2021, 6, 30, 11, 21, 53)], length=48
)], **{})
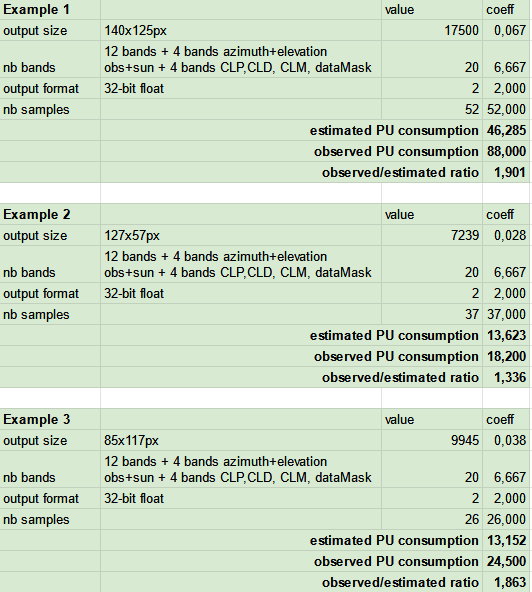
Which leads me to the question : is this possible to pass requests only on the scenes that aren’t cloudy ? Here we see than more than half of the requests are being thrown away following the filter_cloud_task. The maxcc argument from SentinelHubInputTask seems to be suited for the job but its documetation is rather scarce ; is there a place where its exact functioning is documented ?
Also, regarding SentinelHubInputTask, it is described as a “Process API input task that loads 16bit integer data and converts it to a 32bit float feature”. I understand that this operation is done on the servir side, explaining the x2 multiplicator. Thus, what would be the way to switch to 16bit data retrieval using this function ?
Thanks in advance,
J.