good job on adding S1 GRD data to S1, especially for providing data preprocessed to ARD level!
I have tested the processing API for this data, and there is one big problem I noticed - the data for the same are is different depending on the bounding box specified.
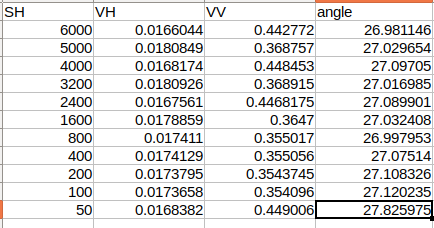
I did a simple test - I defined bbox in UTM, and several other bounding boxes that have buffer distance added around this bounding box (100, 200, 400, 800, 1600, 2400, 3200, 4000, 5000, 6000m buffer). I have sent the same queries for each of these bounding boxes, and then I checked the value of some pixel in the center of the image (so it’s present in all downloaded images). The pixel values are different in every image!
Since Gamma0 for some pixel is dependent on the topography in the local neighbourhood of that pixel, I suspect there is some error in the preprocessing chain you use?
Can you send the examples of these requests and information on which pixel you are looking at, so that we take a look?
I guess that all the requests were for the same resolution, i.e. 10m or 20m? If not, it is expected that the value will change as there is interpolation happening…
Here are for example 3 different bbox parameters that I’ve used:
[371690.0, 5070070.0, 375500.0, 5066850.0]
[371190.0, 5070570.0, 376000.0, 5066350.0]
[370190.0, 5071570.0, 377000.0, 5065350.0]
Once you download the images, I’ve overlaid them In QGis and chose any pixel from the center of the image (so it’s present in all downloaded images). For example, this coordinates:
373475, 5068805
We checked this internally.
The reason for these changes is due to approximate transformations, which are happening in the internal process. A consequence of a design built for massive use, where performance and memory consumption is a major issue.
We believe that these small changes do not really impact the results in a significant manner (i.e. compared to the overall inaccuracy of the data).
I hope they do not cause inconvenience to you.
I’m not sure it’s such a small difference in values, that it won’t impact the outcomes of analysis on this data. Especially if you see how the VV sigma0 is changing. Maybe it’s not such a big deal, but I would refrain from using this data for some scientific analysis and applications, where repeatability and precision are important.
I might carry out some kind of test in the future, to determine the impact this could have on the analysis’s results. If I do so, I’ll post them here.
Well, but this holds true for more or less any kind of data processing, right? But as long as you follow the same procedure (e.g. in your case use the same tiling grid), you should get repeatable results.
I agree with antonijevic.ognjen that this data is not good to use for some aplications that need repeatability and precision. At least this is my case. I was hoping that this would be a issue easy to fix, but I have just discovered this post and I find it rather disappointing.